
(December 20th, 2022)
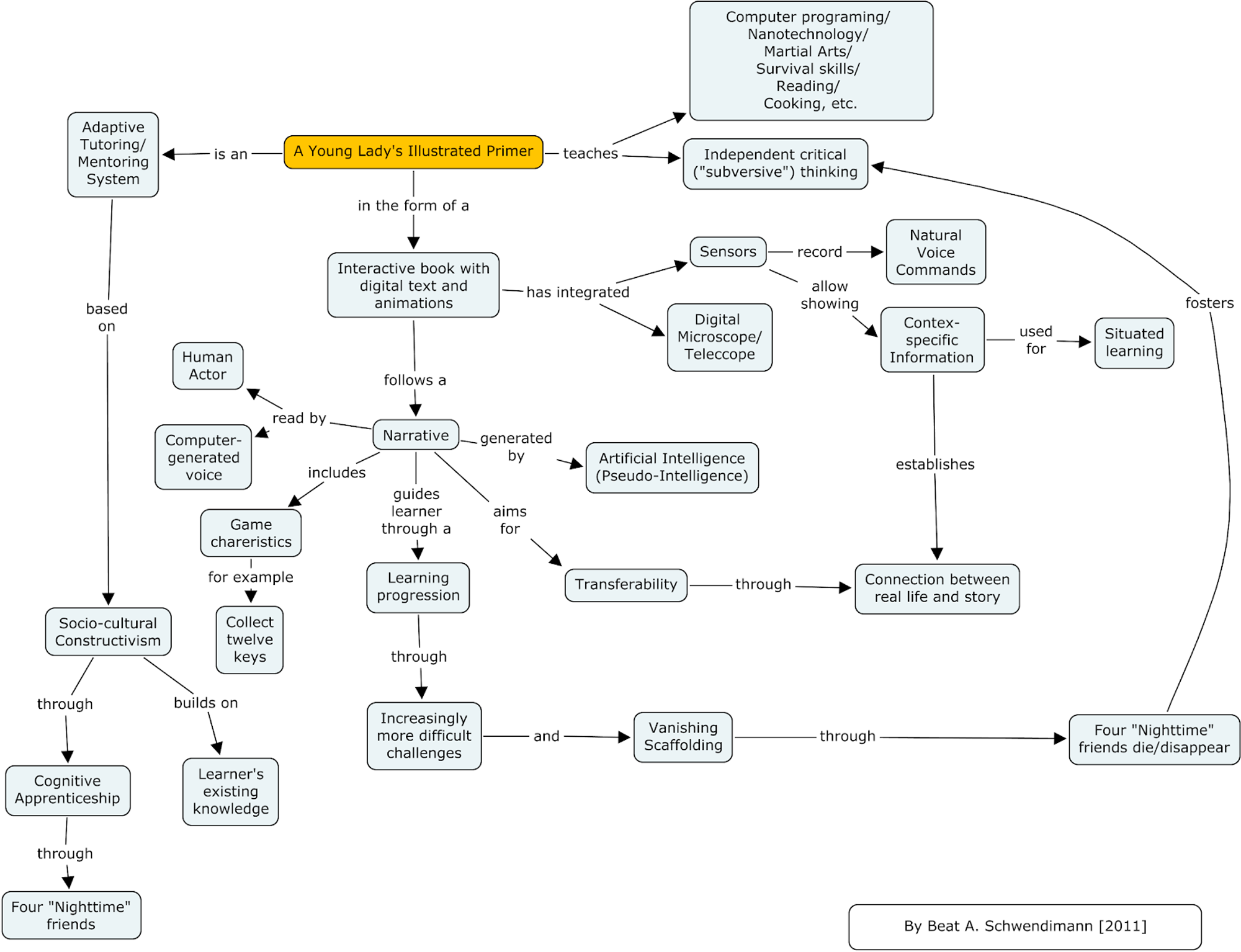
Introduced in the novel Diamond Age, Primer is an interactive digital Socrates that answers with natural language, teaches through allegory, and presents contextual just-in-time info. It’s long been considered an aspirational goal in tech circles as it represents a democratization of teaching and learning spurred forward by machine learning to give everyone a chance in life to grow to their fullest potential. See the following diagram (ProtoKnowledge - 2012) for a complete view of the book version, which is similar to what we aim to do today.
The book Ender’s Game had another version of it, called the Mind Game. It was an advanced computer program played by elite students at the battle school that adapted itself to the interests of each student. One mini-game was the unfair and unwinnable Giant’s Drink game that served to test the player’s perseverance. If the player did manage to get past it, the game had to create this new world that didn’t exist before.
Introduction
This is a V1 for building Primer from inside a well-funded startup with ML expertise. We briefly introduced Primer above. We’ll go on to name missing and necessary technology before enumerating some beachhead products that can be built to a) attract customers that will b) power a data flywheel that c) grows into bigger wedges. We’ll close with risks and target milestones.
Note there is no silver bullet solution for education today; we seek iterative improvements towards a great 1:1 teaching tool with a viable product at each stage. While it is important to be outrageously optimistic, it is also important to be strategically present.
IntroductionTechnologyWhat tech is missing?Form factorsChatbotInteractive book with digital text and animationsIn-ear companionBeachhead productsLanguage LearningEarly childhood expressionBasic MathSportsHistoryRisksMarket RiskTech RiskCompetitive RiskMilestonesAppendixOverall technology reqs
Technology
While the goal is to make a general teaching agent, offering every subject makes it challenging to build the missing parts necessary to reach our goal. For example, what is a curriculum with an agent that responds cogently to anything but does not have a directive to teach anything specifically? Is there really a need to build a holistic profile of the user when the intent is just to respond to the most recent utterance? ChatGPT’s success shows that people will use a good enough agent regardless of there being a curriculum or an imbued sense of the other, but it’s clearly a different product than Primer where the goal is to be a lifelong teaching companion.
What tech is missing?
What then are the additional parts that are necessary to make the Primer product work? This will inform what beachheads we should target. Given that cogent agents can be built from simple algorithms with enough data, RLHF, and a flywheel for generating more data, we need the following modules:
- Coherent and accessible profiles of users: This is necessary for users to accept that they are actually being tutored and not just being fed a rote lesson plan. For example, sometimes the right approach for a lesson is to not teach, but just listen. Can agents that have an agenda (the curriculum) do that? Not yet but with the right data perhaps. This is a thesis behind therapy bots.
- Per-subject teaching curricula: This is necessary in order to present the agent as one with a long term plan and not just regurgitating facts or being a response-bot, both of which are necessary to be seen as a Teacher.
- A measure of confidence in answers: This is necessary in order to gain and keep user trust. A confidence measure can modulate agent responses as well as inform the agent to proactively seek more data (or appeal to devs for such).
- Note that it does not have to be an interpretable level of confidence, which is a much harder research problem. Rather, the agent needs to be sufficiently rewarded or penalized in the conversations themselves. It is much worse to have a confident wrong answer than an unsure wrong answer. It is also worse to have a confident wrong answer than it is good to have a confident right answer. This needs to be accounted for in how it learns each iteration cycle. We want to optimize for retention, not engagement, and the agent itself should be considering that when it answers.
Whatever vertical we take on as a beachhead should be sufficient to address all three of these, with the assumption being that we’re building on top of an agent with near ChatGPT-level quality. That vertical should also be sufficient to provide a flywheel for generating more data, ideally differentiated, as well as allow for expanding beyond that beachhead.
There’s also the question of language. Percentage wise, the best bet to start with is English, as it covers 16.5% of the global population. However, what we see from ChatGPT is that by absorbing the internet, the machine can understand most languages to a high enough efficacy. What we’d actually do is make it clear that we support English only and then go down the list of prioritized languages according to market size and ease of onboarding.
Form factors
This section outlines the potential form factors for the product, their pros and cons, and their technology needs. These are not mutually exclusive, but they do result in different experiences.
Chatbot
An agent that receives and responds with text. It’s exemplified by ChatGPT today, strips away the animations the Primer shows, and just focuses on the text conversation. It’s a lot easier to do than to also provide coherent and consistent imagery and animations while not preventing the product from expanding to include those modalities. However, it’s also a stopgap because a product that incorporates imagery will be empirically more engaging as demonstrated by the last decade of social products.
Interactive book with digital text and animations
This was the original approach detailed in Diamond Age. It is a superset of Chatbot because it still asks us to grok and respond to people through text while additionally answering with imagery. The main advantage to using images is engagement - it’s much easier to keep people interested with visual stimulation. That is especially true of kids, but empirically so for all ages as shown by Instagram and TikTok.
Another advantage is that a tremendous amount can be conveyed with a single well-placed image. Teaching materials, especially parables, do well with images carrying an emotional punch.
A disadvantage is that it’s a lot to bite off and consistency in generated imagery is a considerable tech risk.
In-ear companion
This approach is akin to what we see in the movie Her. A device is input in-ear and is always listening and available to talk to.
One path is to develop a speech-only pipeline where the conversation utterances are input and then the next speech is output. This is not going to work in the near term though because the technology for going from speech to speech is not good enough. Instead, we would use ASR to go from utterances → text-in, then use an LLM to get the next response from text-in → text-out, and finally use TTS to go from text-out → utterance. In other words, we’d be sandwiching a chatbot inside slices of ASR and TTS and have to deal with the related latency costs of using three models.
Relative to chatbots, what we lose in this process is how long it takes to recognize the incoming utterance as text and then form the outgoing speech. That is more notable than it is with chatbots because there is a higher chance to misunderstand. The state of the art in ASR word error rate (WER) is 3-4.5% for Spanish, Italian, and English, which means that it gets wrong at best 3 out of every 100 words. The most frustrating experience is when it repeatedly mishears an important word. That’s when the process loses the user.
Another negative is that it requires an in-ear piece, which can be distracting and dulls your experience of the world.
Another positive is that the user always has the companion at the ready. There’s no need to pull out a phone and type, but rather the user can just tap the ear device and start speaking.
Beachhead products
We consider some product directions, although by no means is this list exhaustive. These were each chosen because they represent a different facet of a breakdown along a) intended age and b) future wedges.
- Language Learning: all ages; there’s a lot of surface area within this space, but it’s seemingly difficult to expand to other industries.
- Early childhood expression: young ages; strong setup for growing with the user and expanding into neighboring wedges, as well as diving into imagery from the start.
- Basic Math: all ages, dominantly kids; can expand to areas where the goal is to assess technical understanding through problems, e.g. Chess or reading comprehension.
- Sports: all ages but dominantly teen to mid twenties, especially helps target the large percentage of the population physically inclined rather than intellectually inclined; wedges quickly into image-focused sectors.
- History: older ages; lots of future wedges that the product could grow into like finance, research, and fact-finding.
Language Learning
Description: Primer teaches languages to all ages. It would talk with TTS, listen with ASR, and show the words on the screen like subtitles. Beyond the initial learning ramp-up of the basics, it would then switch to speaking in the target tongue. In other words, it would duplicate the teaching experience students get on services like Italki or HelloTalk.
Pros:
- Answer confidence: It mostly doesn’t matter whether the agent says something that’s wrong, as long as it doesn’t say something grammatically incorrect.
- User profiles are about remembering their speaking capabilities and the stories they say during conversation. There is no expectation that the teacher keeps a deep detailed understanding of what the student is sharing.
- Teaching curricula has been refined for this over many generations of products. This can be tapped into, but at some point it really just becomes about having conversations with students, and that’s where these models shine.
- Flywheel: There’s a large market for this and lots of demand for it to be cheaper, so easy to iterate on all of those user experiences. Initially focusing on a strategy supplanting HelloTalk’s offering would contribute directly to an improving flywheel.
- Market: There’s a terrific amount of data online and companies that can be partnered with for further access to data and iteration.
Cons:
- Expansion: It’s challenging for this to extend to other non-language domains. The requirements are much lower for each of the hard parts listed above and it doesn’t obviously branch into other topics of learning.
- Technology 1: The best version of this has necessarily strong TTS capabilities, which doesn’t obviously help in other domains.
- Technology 3: ASR is also required, and models today have difficulty with broken language because those are unusual for the language model they use to fix what’s been said.
- Technology 2: This requires robust safety gates given its all-encompassing conversational nature.
Early childhood expression
Description: Primer teaches kids age 3-10. The goal here is not to teach a specific subject but instead gain the trust of kids and parents from an early age with interactive and sticky experiences that inculcate kids to the experience of using Primer. One example of this is a painting assistant that helps children make expansive engaging worlds using ASR, image generation, image detection, and motion generation.
Pros:
- Answer confidence: Getting wrong a character’s response to a child’s story results in more imaginative tales. Getting wrong a picture of a dinosaur wearing a skirt just means that the child recreates it. In other words, this isn’t a big deal for the initial products.
- User profiles: This is a great way to learn how to reliably build user profiles. Kids speak with simple words but their stories can be challenging to piece together without long term memory. However, basic prompts can guide the kids to answer questions so that our agent can form a complete picture of their psyche. To grok either their drawings or their talking requires a back and forth conversation to divine what is the actual meaning.
- There is often some set of prompts that can be used to clarify, e.g. “Why did you draw the swings?” <Because it was snowing> “How does the snow relate to the swings?” <Snow stopped me from playing outside yesterday>. In that conversation, the child was communicating their outsized feelings about not being able to play outside through an apparently obtuse drawing that was exceptionally clear to them.
- Teaching curricula: While the teaching curricula for this can be a challenge, it’s not as important to get right as it is to nail the interactive parts so that kids want to come back to it. From there, a lot can be built, including reading comprehension and simple math skills before branching into more complex subjects.
- Expansion: There’s a lot of internet data on how adults talk, but not as much on how children do. This would get at that and open up the possibilities to a lot more than just adult learning. It branches into many other areas because the product already has the child’s attention and can grow with them into new domains like early Math, Reading, or Language Learning.
- Flywheel: The data gathered within this experience will be specific to children and hard to gather otherwise. This includes audio and drawing input. That is similarly true about what to draw in that the image generation and detection models evolve according to what kids want. However, the real flywheel is in the answers the kids give to the prompts. Their answers can be mined to inform downstream questions that end up becoming teaching topics.
- Market: The market for early child education is very large, with most of the offerings being poor for child growth (e.g. Cocomelon) but excellent for keeping kids from bugging their parents. We can do better on the former and get parents to love it even more.
Cons:
- Technology: Kids at this age cannot reliably read or write, so the communication medium has to be through ASR and TTS. That can be problematic wrt latency and user experience.
- Teaching curricula: We’re unlikely to learn what makes a good teaching curriculum and how to produce it for other domains until we move into real teaching and not just assisted creation.
- Market: It’s challenging to keep a kid’s attention. The fun thing du jour can be blase to the next generation.
- Technology: This requires robust safety gates.
Basic Math
Description: Teach kids math, starting with basics like numbers and fractions, then moving on to Algebra and beyond. The basics, before entering into proofs, is arguably similar to learning chess and reading comprehension in that problems/positions can be shown to the learner and solutions evaluated in order to assess their level. These could even be done in parallel to offer an entertaining break from the other as the kid grows. To be clear, this type of adaptive learning is not a new concept and companies are already trying to do this without LLMs.
Pros:
- Teaching curricula: There is a tremendous amount of basic math problems in the public sphere and we can quickly evaluate them in order to hone in on where the learners’ abilities lie. From there, the next set of problems can be shown to the learner in different ways until they get the answer. The hardest part of this is helping them stay confident and present without giving them the answer.
- Market: This is the same market powering Kumon. There is a large number of kids around the world whose parents want them to STEM from the time they are in the womb.
- User profiles: The profile of the student can likely be tied closely with their speaking style and otherwise given subsidiary importance to the curriculum, which is serving double duty as engendering the user profile as well.
- Flywheel: There’s a large amount of data online and in books, and every exchange is an opportunity to grok where a learner’s ability lay as well as better hone the model’s understanding of the nodes in the learning process.
Cons:
- Answer confidence: Being confidently wrong is bad, very bad. As soon as the model is wrong in this domain it loses all kinds of trust.
- Expansion: It might be challenging to extend beyond basic situations because the solution outlined here relies on the problems being quick, self-contained, and providing singular answers.
Sports
Description: Coach Primer helps athletes reach their full potential. At large, the goal is to replicate a 1:1 Coach aside from the physical placement that coaches sometimes do. A hard task is to ingest training videos and produce detailed analysis of what the aspiring athlete did that session, e.g. how many shots they made from every part of the court, as well as what they need to work on next. The near-term vision is to replicate what remote coaches do in businesses like future.co where they answer questions from muggles doing recreational fitness.
Pros:
- Answer confidence: It is important to get answers, but it is even more important to be confident about what the athlete should do next. A lot of sports and fitness coaching is about experimenting fast with what works for each person’s body. That’s where an LLM’s unbridled confidence can shine when matched with a strong evaluation system.
- Teaching curricula: Every sport or expert movement has its curriculum for how to improve. Expert coaches can quickly evaluate where your handstands are bad or what facet of your skating needs to be better, and they do it just by watching. This can be developed with video as well.
- Expansion: A solution to the near-term vision could cover other domains because it’s largely a chat box. I worked on this a year plus ago when I was building OfficeHours.help, a similar product for Machine Learning answers.
- Flywheel: Once there is a robust algorithm producing insights of high value, then this should be very strong as there is no comparable product and video advantages will compound swiftly due to how unwieldy it is to manage video and provide robust solutions to these problems.
- Market: A solution here would also apply to other domains with VideoQA, like surveillance and media. Those are very large markets, albeit it would be moving away from the Sports Coach vision.
Cons:
- Technology: No company has ever enjoyed the infrastructure challenges associated with video products, however those are solvable.
- Technology: The most valuable products are for soccer, football, and basketball, all team-oriented, with lots of apparatus interactions, and consequently requiring inordinately more challenges than what most research to date has addressed.
- Flywheel: It’s non-trivial to start this flywheel because a lot of video data is needed, data which is both computationally unwieldy and difficult to understand. It’s also unclear how much data is needed to produce insights of high value.
- User profiles: This is challenging. On the one hand, that means it will be a way to learn how to do it. On the other hand, it’s a commonly cited problem (by coaches) of why solutions in this space fail to really take hold; Saying whether someone is doing a technique right or wrong is heavily dependent on your profile of them, which includes unique body aspects.
- Market: Team-oriented sports are a large market, but that’s where this technology will be least capable. The individual sports are each a good candidate for Primer, but those markets are small and each one of them is its own challenge.
History
Description: Teach history to college age and above. This expands to broader questions like “teach a thesis for how the world works” or “help evaluate a thesis for how the world works.”
Pros:
- User profiles: This is a good domain for learning user profiles. It’s helpful to model what the user knows and then guide them through history with that in mind, but it’s not an imperative to the product succeeding. Students attain a deep understanding of history without their professors ever even knowing their name.
- Teaching curricula: This is quite important, and fittingly plenty of public curricula (or cheap) have been developed for a tremendous amount of history.
- Flywheel: Per-topic flywheels are clear, although it’s less obvious if their defensibility crosses topic walls.
- Expansion: The wedges here are phenomenal. A capable teacher for teaching to a thesis expands almost immediately across many industries, from finance to politics to reporting. So the wedges grow quite quickly from a toy to an important part of society.
- Technology: Most of the technology is readily available. The main missing ingredient is a strong search engine on top of LLMs
Cons:
- Answer confidence: Similar to Math, being confidently wrong is bad, very bad. As soon as the agent exhibits such behavior, it loses all kinds of trust.
- Market: The market for history is low; at best there’s docutainment and college history classes. However, as mentioned above in Expansion, a Primer that can teach or evaluate theses in general is valuable to a wide range of industries.
Risks
Market Risk
The biggest risk is that the initial wedge(s) fail to gain traction and the company runs out of money because it couldn’t build something people wanted. Primer is not ready to spring forth today. Rather, it needs to be coaxed into existence through successive iterations by a company built to last for a long time and dedicated to this goal through strategic directives that culminate in a wonderful 1:1 teaching experience.
Tech Risk
There are real concerns around tech risk because there are still necessary components for Primer for which we do not have suitable solutions. A great example is research into confidence and answer certitude. If we are going to build a teacher and not Dunning Kreuger as a Service, then we need this to work. We further need it to do efficient active learning.
Competitive Risk
Where would competitive risk come from? OpenAI is an obvious one; they’ve been hiring teams to build products and this is a direction in which they have the research expertise to accomplish.
Another is character.ai. Today they are providing foundation models for other groups to build characters, which can (and do) include a variety of teacher-type experiences. As we can see from the above detail in the Strategy section, there’s a large jump from character to the full product experience necessary to power Primer. While it’s possible that someone builds Primer on top of Character, it’s also in the cards that Character itself would spend engineering resources to build Primer given their accumulating expertise.
A third are companies in one of the aforementioned verticals, or even in teaching itself. An example is speak.com, who has been teaching English to South Koreans and just raised capital from OpenAI’s venture arm to build LLM services into language learning. There’s less risk here though because they can stay in their lane and build a fantastic business just selling to language learners around the world. Another example is a company like Neeva, who are building a new search engine. They could wedge into this by building the thesis evaluation machine referred to in the History section.
Milestones
In all of this document, I have been assuming the existence of LLMs that are on par with, or close to, that of ChatGPT. That is a necessary first milestone.
The second milestone is choosing an initial wedge and sticking with it. If I was tasked with choosing one today from this list, I would pick either Language Learning or Early childhood expression. In both of these, there isn’t an imposition to solve the very hard technical risk problems just yet. It is of course likely though that there are considerations that would change this decision, e.g. special access to particular datasets, unique partnerships, etc.
With Language Learning, there is an immediate need and market to serve across ages, plus the scope and variety of data in those chats is very large, which helps for the generalized solution (albeit not for another specific vertical). Working with a language teacher can sometimes feel akin to working with a therapist but the conversation is two-sided and prompts can get the students talking for a long time. There’s also no implied private data because the intention is benign.
With early childhood expression, there is heavy demand for educational content that engages kids, as we see given the sheer quantity of [growing] content on the market today, but it’s also a very tough middle ground to navigate. Beyond that, this pursuit brings to bear all of the advancing machine learning capabilities in an environment that doesn’t require that any one of them is airtight and then generates lots of hard-to-get data around child interactions. Those are strong attributes for an initial product wedge.
The third milestone is making an MVP demonstrating the target product. For language learning, that would be akin to a basic italki or hellotalk conversational partner. For early childhood expression, it would be a tablet app that interfaces through ASR with creative children to play with text → image models.
The fourth milestone is implementing and controlling a robust data flywheel. That is dependent on which direction is chosen, but each has their own variant.
Ensuing milestones are all about steadily improving the product and hiring the right leadership to ensure that we remain on the path towards building a digital Socrates that can power the Primer and not exiting at an earlier pitstop. That pitstop may be more lucrative today, but likely less lucrative and less impactful in the long term.
Appendix
Overall technology reqs
This section recaps the prior discussion and details the overall technology requirements.
At minimum, we need:
- A tablet device with enough processing power, likely aided by cloud infrastructure.
- A module for understanding language input, likely through text.
- A module for producing a coherent response to a series of utterances.
- A knowledge base accessible to the agent that can be updated in real time with new facts.
- Reliable confidence in its answers.
With the above, users can carry with them a portable agent with which they can converse and retrieve informed answers to their questions, as well as understanding when the agent isn’t sure of its knowledge.
Today, we have much of this with the advent of LLMs. What’s missing are 4) an accessible and updateable knowledge base and 5) reliable confidence in the answers.
We can build knowledge bases that represent accumulated conversational understanding, which is necessary towards user understanding. We can’t yet do LLM + knowledge bases that know how to update the LLM’s factual understanding. That’s a near-term challenge for the research community and is spurred by commercial need.
We don’t actually need the confidence measure to provide strong services that are akin to an assistant, but we do need it for a full-fledged Primer.
Those minimum requirements miss a number of features of Primer, such as:
- Voice input.
- Voice output.
- A teacher persona.
- A curricula experience.
- Visuals and animations.
Voice input and voice output are given by ASR and TTS, which adds the following to our list:
- Strong ASR across languages with low enough WER, even for kid voices.
- A TTS system with prosody that passes a threshold of quality.
Note that these are definitely requirements if targeting children younger than seven or kids with learning disabilities as they are slower to read or type.
The teacher persona needs the following:
- An animated teacher character with
- Animated movements, prebaked as necessary.
Optionally, it has a per-user memory module in order to have a coherent picture of what the student likes, doesn’t like, etc. This is the best version of the teacher and is arguably the hardest part of the entire pursuit.
The visuals and animations asks for the following:
- Create imagery given text concepts that
- Is consistent across scenes and
- Does not confuse the user with extraneous components.
Optionally, it also can do video and motion generation.